想要进行无损滚动更新需要保证一下3点
- 应用支持优雅退出(收到退出信号时不接收新请求并且要处理完已经接收到的请求)
- k8s正确配置readnessProbe就绪探针
- 添加生命周期函数preStop添加一定的延时, 比如preStop.exec.commend: ["/bin/sh", “-c”, “sleep 10”]
主要原因为Kubernetes 在终止 Pod 时的操作顺序是
- 标记 Pod 为 Terminating 状态:当 Kubernetes 接收到删除 Pod 的请求时,它会将 Pod 的状态设置为 Terminating
- 执行 preStop 钩子:如果 Pod 定义了 preStop 钩子,Kubernetes 会立即同步执行这个钩子
- 并行更新 Endpoint:在 Kubernetes 标记 Pod 为 Terminating 状态的同时,Endpoint Controller 会异步地从相关的服务端点(endpoints)中移除该 Pod 的 IP 地址。Kube-proxy 也会开始更新其网络规则,以停止向该 Pod 转发流量
- 发送 SIGTERM 信号:一旦 preStop 钩子完成,Kubernetes 会向 Pod 中的容器发送 SIGTERM 信号,告诉容器开始优雅地关闭
- 等待或强制终止:如果容器在终止宽限期(terminationGracePeriodSeconds)内没有关闭,Kubernetes 会发送 SIGKILL 信号强制终止容器。
%% Kubernetes Pod 终止流程(Endpoint更新与preStop并行)
graph TD
A[用户/系统删除Pod] --> B(标记Pod为Terminating状态)
B --> C[[Endpoint控制器异步移除Pod IP]]
B --> D{执行preStop钩子}
C --> E[停止流量路由到Pod]
D -->|同步等待完成或超时| F[发送SIGTERM信号]
F --> G{进程处理SIGTERM}
G -->|异步处理| H[等待退出]
H --> I{是否在terminationGracePeriod内退出?}
I -->|是| J[Pod终止完成]
I -->|否| K[发送SIGKILL强制终止]
K --> J
%% 同步/异步标注
style B fill:#c9f7d4,stroke:#2d8a3e
style C fill:#e3f2fd,stroke:#1e88e5
style D fill:#c9f7d4,stroke:#2d8a3e
style F fill:#c9f7d4,stroke:#2d8a3e
style K fill:#c9f7d4,stroke:#2d8a3e
style G fill:#f8e5d4,stroke:#cc6b2c
style H fill:#f8e5d4,stroke:#cc6b2c
注:
关于endpoint已经iptables或者ipvs的操作是kube-porxy的操作
关于pod停止和生命周期是kubelet的操作
所以会出现下面的问题(网络操作和pod生命周期是异步的)
添加延迟的原因主要是preStop和更新endpoint是异步进行,如果没有设置preStop就会出现修改endpoint和发送SIGTERM异步进行, 当应用收到SIGTERM时就不会接收新请求处理完老请求后退出,但是此时endpoint还有可能没有修改完成,就会导致一部分请求流入了即将退出的pod,而且无法响应请求,这时候这部分请求就会损失
没有配置preStop的情况
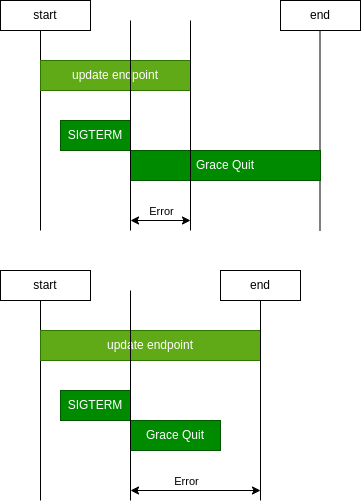 当应用接收到SIGTERM就不处理新请求了,从收到SIGTERM到更新完endpoint前,这部分请求都会异常
当应用接收到SIGTERM就不处理新请求了,从收到SIGTERM到更新完endpoint前,这部分请求都会异常
有配置preStop的情况
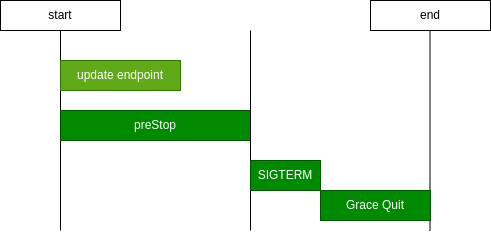 这时候能保证应用收到SIGTERM前endpoint已经更新完成,这样就不会异常了
这时候能保证应用收到SIGTERM前endpoint已经更新完成,这样就不会异常了
这个延时就是为了能让endpoint修改完成之后pod再响应SIGTERM进行优雅退出,此时新的流量已经不会在进入该pod了
注意:
如果观察到preStop的延迟没有按预期执行,需要看下k8s配置, 是否是格式问题(比如[’ /bin/sh -c sleep 10’], 正确的是["/bin/sh", “-c”, “sleep 10”]),或者镜像不支持sleep命令
lifecycle:
preStop:
exec:
command: # 看下镜像是否支持这个命令,如果不支持就在应用中添加sleep,进行调用
- /bin/sh
- '-c'
- sleep 10
注意:
如果发现pod在被标记Terminating时几秒钟后发现网络不可用可能是在使用istio等sidecar代理,注意是否sidecar提前退出了,导致网络不可用